
导语
华南零售行业全渠道联盟,简称“南零商盟”,华南时尚行业CIO联盟和广州鞋服行业信息化联盟、华南CIO联盟、华南智慧商品联盟唯一联合指导交流社群,汇聚服饰、时尚行业新零售全渠道搭建双方的精英联盟;
| 专心 | 专业 | 专研|
时尚行业信息化第一微信公号
点击这里->-> 隆重招商!2019年7月底将举行第四届全国时尚行业转型高峰论坛暨华南时尚行业CIO峰会!
第97期“南零商盟”微谈会于2019年6月20日晚上8点正式开播,本次分享嘉宾是来自速鸿科技林浩永总为大家分享“应用服务的黑匣子”。
嘉宾介绍



黑匣子作用
飞机失联或是遇难的情况,是我们现在无法完全避免的事情。每当遇到这样的事情,最先处理的事情,是救援,第二必需处理的事是找到黑匣子。
那飞机的黑匣子是什么呢?其作用又是什么?
说白一点就是飞机的监控器,是记录飞机的所有数据,一般包括两方面的数据:一是飞行数据,记录飞行的一切资料,飞行高度、速度、航向、垂直过载、俯仰、倾侧、操纵面的偏转角、升力、阻力和发动机功率等;第二是录音数据,记录了机务人员的所有声音。
如果没有黑匣子会是怎样子。一是没办法快速援救,飞机飞到哪里都不知道,即使有大量的人力物力也没用。二是不知道飞机失事的原因,那就会导致没办法修复问题,还有就是没办法定责。
例如,20多年前,挪威上空一架军用飞机发生爆炸,飞机坠毁,飞行员身亡。挪威当局赶到出事现场,从飞机残骸和飞行员的尸体中,辨认出这是一架某大国的军用侦察机。挪威向某大国提出抗议,某大国矢口否认。后来,挪威找到了飞机上的黑匣子,从黑匣子记录的数据进行分析,揭露了真相。某大国在铁的证据面前只好认错。
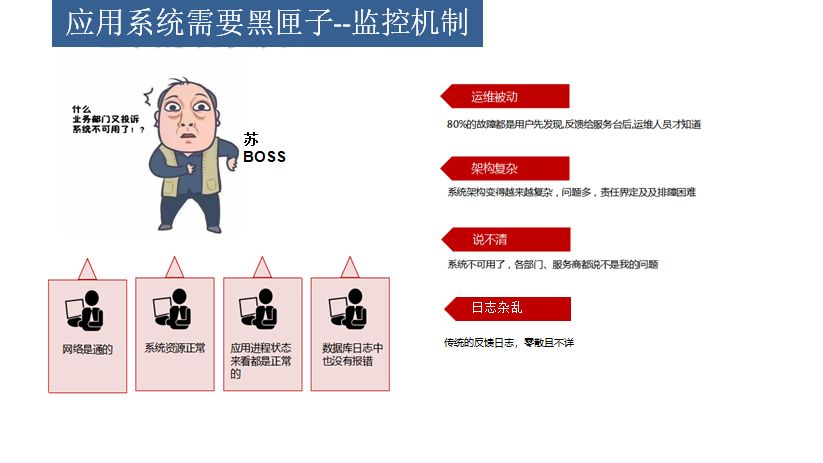
服务器也需要一个黑匣子
同样道理的应用服务也是需要一个黑匣子。在座的各位大部分都是企业里面的CIO,都是带领团队处理各种各样的系统故障,不多不少都遇到以下的问题:
1. 运维被动。
我接触过一个客户,有一个应用系统过一段时间需要重启才能正常。系统供应商找不出问题,也以别的客户没同样问题为由,而不处理,导致业务部门经常投诉至科技部,他们才去重启。运维太被动,不能主动先于业务部门发觉而处理。
2. 架构复杂
现在的系统为解决越来越复杂的业务和越来越大的访问量,系统架构越来越复杂。如一个简单的中型系统,可能会6台以下的服务器,一个服务器可能是两三个应用,三两个负载,几个缓存集群,几个数据库集群,甚至用到几台消息队列。一出现故障,根本没办法定位问题。
3. 难以定责
网络排查了,服务器资源排查了,日志查看了还是定位不到,系统还用不了或不稳定,咋办呢?网络人员,系统运维人员,开发人员,供应商?没真凭实据,真不好说。
4. 一般的产品日志写的都不详细。加外并发量大起来的话,几个G的日志,想要找到自己想要的日志确实非常难。而且如果涉及几台服务器的话,就是把几十个G的日志都下下来看,对运维和开发都造成很大压力。
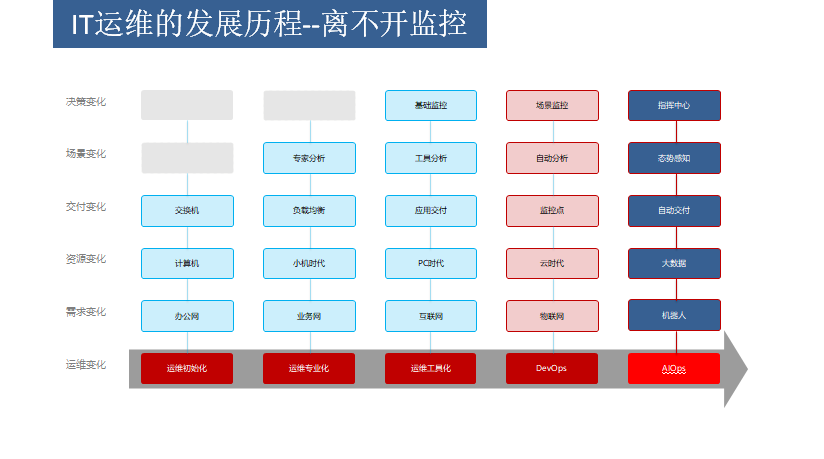
通过IT运维的发展历程说明一下监控
前两个是”运维初始化“和”运维专业化“是对于很久以前的微小型运维的概念,那时只是装个小PC机,接接网络,配置网络之类,根本没有监控概念,也不需要监控。
到第三阶段”运维工具化”,这个时候随着系统服务器的增多,和架构变复杂了。技术问会建立自已的运维团队和开发团队。运维团队要管理大量的务器,网络设备等,必需要监控工具来附助,实时知道设备的状态,能及时定位和处理设备故障。
第四个阶段就DevOps,就是Dev就是指开发,Ops就是指运维,是开发和运维的高度柔在一起。在制度上的表现,第三阶段是开发部和运维部两条线了,即开发部管A,B,C几个项目,运维部也管A,B,C几个项目,到这个段阶会是A项目划入专职的开发人员,和运维人员。在这此阶段随首运维系统的强大,监控的深入,运维效率几何级别的提升,使“部署–监控–告警–处理故障–再部署”达到一个快速闭环。这其中监控的深入间重中之重的。在这阶段也使APM监控提到至关重要的位置。
第五个阶段是AI运维,是近几年几提出的,一般在大型的互联公司使用。这里最主要的两个概念是大数据和人工智能。正如上面所说的,对于日志可能一个就几十个G甚至上百个G,一个月下来就几个T,没有一个分布式的大数据平台在后面支撑,结果是一查数据就死机。有了大量的数据就可以用人工智能排问题。一个简单的场景是,如果应用假死了。运维人员会通过大量的监控指标,阀值去排查问题。人工智能直会跟你说网络故障了或JVM的堆内存配置过小了。
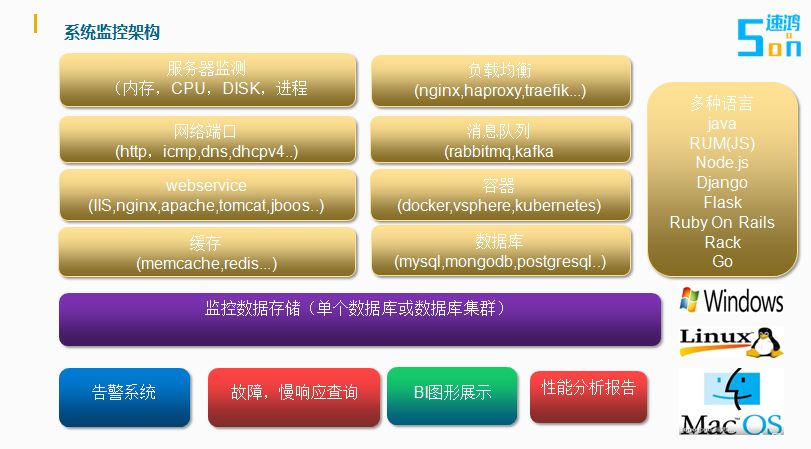
监控系统的架构
这里简单说说监控系统的架构。说是简单就三部采集,存储,展示预警。
但其实要做好是非常复杂的。对采集来说,首先是监控的系统有很多,有linxux,windows,MAC OS,要监控的应用类型又是多种多样硬件的监控,负载均衡,网络端口,消息队列,webservice,虚拟容器,数据库等。每一类型又有多种的应用,如数据库就是oracel,sqlserver,mongodb。开发语言也有十几种。简单运算一下,如有30种应用,两个操作平台,都需要60个采集模块。
监控数据的存储,对于中型系统来说,一个月的就是几百的G的,没有一个良好的分布式大数据平台,根本跑不起来,那么对于后面的数据展示和告警这些用户最真接,最实在的功能造成很大的影响的。
最后一层是运维人员最直接接触的功能,如应用拓扑逻辑发现和可视化。能自动识别应用在执行的过程中涉及的软硬件架构和组件,并且可以描绘出应用交付链中相互通讯的各种组件的访问路径,通过调用链的实现,形成拓扑图并进行可视化,直观地展示应用的拓扑逻辑。可以通过定量的指定设定,达到系统的预警,甚至AI来完成智能监控报警和处理。
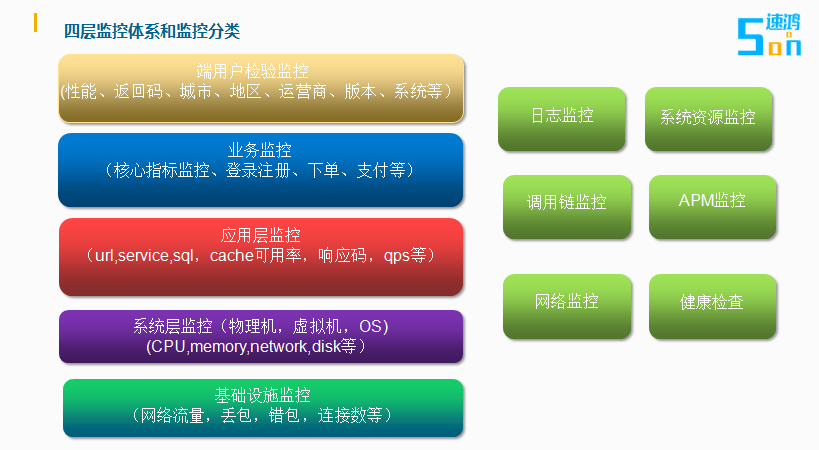
四层监控体系和监控分类
根据应用系统的运行过程,我把监控体系统分成以下层:
第一层是端用户的监控。其就应用系统的基本触发点。在这里我们可以监控到用户的潜在信息:如用户在哪里使用的系统,使用的版本是什么,根据响应时间和返回码可以判断用户使用流不流畅,会不会经常报错。
第二层是业务监控,服务商来说我想知道注册人数,登录频不频繁,在天猫还京东下单较多,哪类人通常去天猫下单。
第三层是指针对应用层的监控,一般传统的监控供应商没有这层监控,这个是更高级别的监控。对于一般用户来说,应用程序就是一个黑箱子,操作系统,系统有反馈,但里面是怎运的怎样,为什么系统响应用户那么慢,或者给用户错误响应,都不知道。但在应用层做了APM的监控。就可以很快的回答这些问题。与传统的监控不一样APM能监控到应用运行时每一个时间切面的运行状态。知道系统第一个请求的数据处理状状,访问了哪台数据库,访问时间是多少,运行逻辑是否不正解,对服务的资源损耗多少等。对于应用的运行的疑难杂证是良方妙药。
第四层就基础设施监控,就是传统的监控服务器的CPU内存,磁盘IO等,或监控网络的流量情况,网络是否连通等。
一个好的监控系统能帮大家什么?
一个好的监控系统,能帮科技部的管理者对自己管理的所有的应用、设备的运行状态了如指掌;能简化日常运维工作,节约成本;遇到问题,能快速定位问题,提高满意度。甚至是带是人工智能运维系统能自动判定问题的根源,自动的处理问题。
注:以上内容摘选自南零商盟分享会,转载仅限学习分享;
如产生版权问题,请联系我们处理;
文章不代表”华南时尚行业CIO联盟“立场!

本篇文章来源于微信公众号: 时尚行业CIO

 关注微信公众号
关注微信公众号