

DeepSeek 推出的新模型 DeepSeek-R1 在全球 AI 领域掀起了巨大的波澜,仅用十分之一的成本就达到了 GPT-o1 级别的表现。
据一位 Meta 员工在 teamblind 爆料,DeepSeek 让 Meta 的员工陷入了恐慌,工程师们正在疯狂地剖析 DeepSeek 的模型,管理层开始质疑高额训练成本的合理性,因为 DeepSeek 对外宣称只用 500w 成本就能训练出 R1 模型,而这只是 Meta 一位高管的年薪。

很多业内人士甚至喊出了 “DeepSeek 接班 OpenAI” 的口号。因为它们做了 OpenAI 本来应该做的事:开源。

更令人惊叹的是,DeepSeek-R1 在训练过程中展现出了“顿悟时刻(Aha Moment)”,这种突破性的涌现能力和自我进化潜力,不仅体现了模型的强大实力,更在 AI 领域具有里程碑意义。
1、历史发展
在 OpenAI-o1 推出之后,强化学习成了业界最关注的方法。而 DeepSeek-R1 是首个在开源模型证明这一方法行之有效的模型。我们先来了解一下,训练 AI 的推理能力传统的方法通常有以下几种:
-
1、思维链(Chain-of-Thought, CoT)训练 -
在 SFT 阶段加入大量带有推理过程的示例 -
让模型学会像人类一样一步步推理
-
-
2、神经网络奖励模型(Reward Model) -
使用复杂的奖励模型如 PRM(Process Reward Model) -
对模型的推理过程进行评分和奖励
-
-
3、搜索算法增强(Search Algorithm) -
使用蒙特卡洛树搜索(MCTS)等算法 -
在多个可能的推理路径中寻找最优解
-
-
4、基于人类反馈的强化学习(Human Feedback Reinforcement Learning, HFRL) -
收集人类对模型输出的评分和反馈 -
使用这些反馈数据训练奖励模型 -
通过强化学习让模型学习产生更符合人类偏好的输出
-
以 AlphaGo 为例,它采用了多种推理能力训练方法的组合:通过监督学习训练策略网络学习人类棋手的走法,使用蒙特卡洛树搜索(MCTS)在对弈过程中探索最优策略,并结合强化学习让模型通过自我对弈不断提升。其中 MCTS 算法通过模拟大量可能的下棋序列来评估每个动作的价值,而策略网络和价值网络则为 MCTS 提供启发式指导,形成了一个高效的决策系统。这种多层次的训练方法使 AlphaGo 能够在围棋这个高度复杂的博弈空间中展现出超越人类的推理能力。
2、强化学习
DeepSeek-R1-Zero 开创性地采用了纯强化学习的训练方法,这是一个颇具挑战性的选择。与传统方法不同,它摒弃了预先定义的思维链范式(Chain of Thought)和监督式微调(SFT)过程,转而依托简洁而高效的奖惩机制来塑造模型的行为模式。
2.1、组内策略优化(Group Relative Policy Optimization, GRPO)
想象你有一群学生(AI模型),老师(训练算法)想通过作业(强化学习)提升他们的解题能力。传统方法需要给每个学生单独打分(评论模型),但这样太耗时耗力。于是,老师换了一种方法——GRPO:
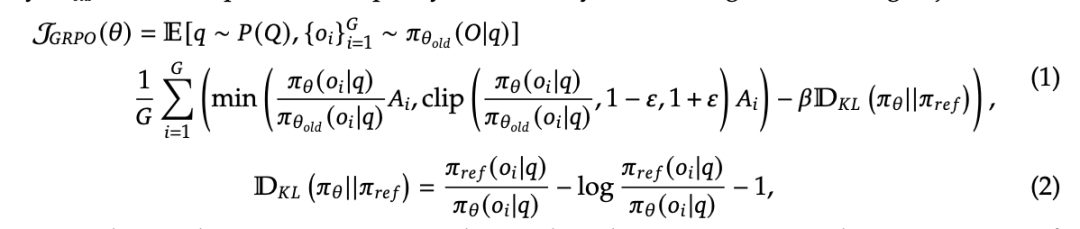
-
组内比较代替单独打分 -
老师每次出一道题,让所有学生(旧策略)都提交答案(输出组) -
根据这些答案的整体水平来评分 -
如果某个学生的答案比组内平均分高,就奖励 TA -
如果答案比平均分低,就提醒 TA 改进
-
-
保持稳定,避免”放飞自我” -
为了防止学生突然改变解题风格(策略突变) -
老师要求新答案不能和旧答案差异太大(KL 散度惩罚) -
这就像说:”你可以进步,但不能完全推翻以前的思路”
-
这种训练方法最令人惊叹的是其自我进化能力:通过组内比较机制,模型不断探索和优化解题策略,就像一个天才学生突然领悟到解题的关键,模型也能在训练过程中发现更高效、更优雅的解题方法。
2.2、奖励模型(Reward Modeling)
DeepSeek 的 Reward Modeling 主要关注两个方面:
-
答案的正确性:对于数学题或编程题等有明确答案的任务,Reward Modeling 会检查模型生成的最终答案是否与正确答案一致。 -
格式的规范性:DeepSeek 要求模型在生成答案时,必须将思考过程放在 <think>标签中,最终答案放在<answer>标签中。
2.3、模型自我进化
以上一系列创新性的训练方法在实践中取得了令人瞩目的成果:在包括 AIME 在内的数学竞赛题目和复杂的编程任务中,经过 RL 训练的 DeepSeek-R1 模型展现出惊人的进步,其准确率从最初的 15.6% 显著提升至 71%,实现了质的飞跃。
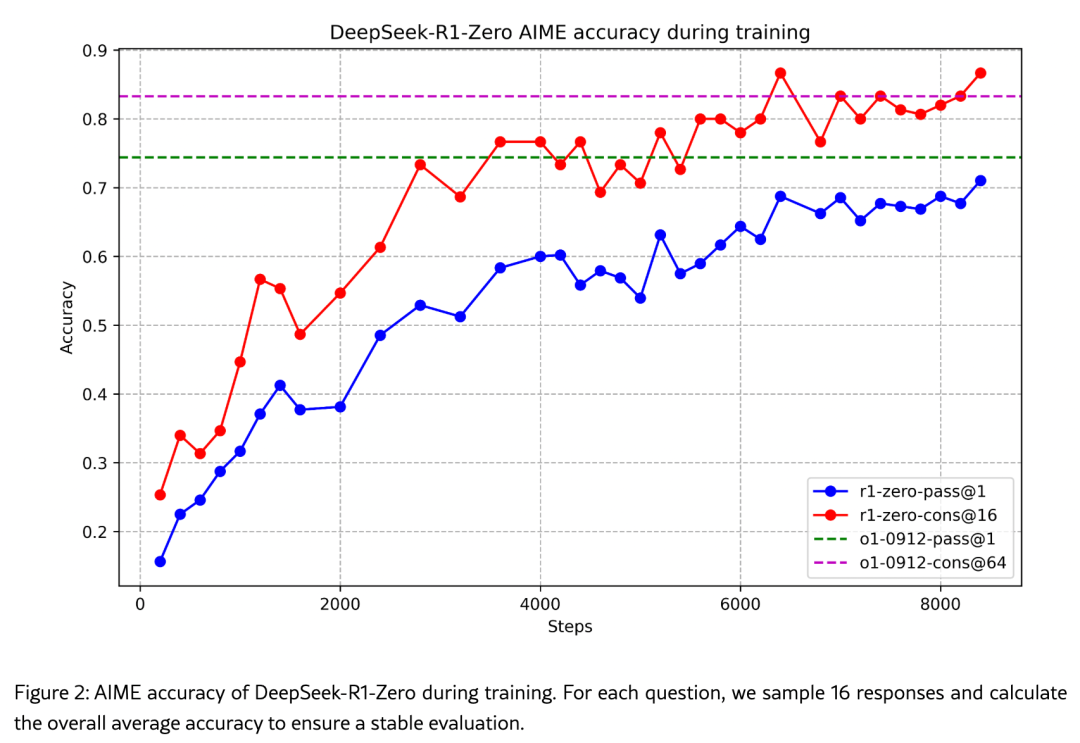
因为 AIME 竞赛题目不仅需要深厚的数学功底,更考验解题者的创造性思维。这类题目往往需要通过巧妙的推理过程找到解决方案,而非简单地套用公式。这证明了模型具备强大的推理能力。
更为引人注目的是,模型展现出了类似人类的智慧特征:它能够根据问题的复杂程度自动调节响应长度。这并非简单的模板套用,而是对问题本质的深度理解。就如同人类在面对简单的加法运算时能够快速作答,而在处理复杂微积分问题时会投入更多思考时间一样。
2.4、顿悟时刻(Aha Moment)
在 DeepSeek-R1-Zero 的训练过程中一个特别有趣的现象是“顿悟时刻(Aha Moment)”的出现。在处理一个复杂数学表达式 √a - √(a + x) = x 的问题时,模型突然停下思考说:
"Wait, wait. Wait. That's an aha moment I can flag here"(等等、等等、这是个值得记录的顿悟时刻)
随后重新审视问题。

这是一个非常激动人心的表达,难以想象这种情感化的语句竟然是 AI 在完成一个数学任务。简直像是某个科幻电影的开头。
这种行为模式与人类在解决复杂问题时的 “aha moment” 惊人地相似:当我们突然理解了问题的关键所在,会不由自主地停下来重新思考。
就像一个天赋异禀的学习者,不依赖现成的解题模板和详细指导,而是通过持续的探索与尝试,在反馈中逐步构建自己的思维链。
3、影响与启发
对学术界来讲,DeepSeek 的成功提出了一条探索方向:传统的 AI 训练太执着于让 AI 模仿人类的思维方式。也许未来的 AI 研究应该更多地关注如何激发 AI 的创造力,而不是仅仅依赖于传统的监督学习。
与此同时 DeepSeek 也成为大国科技竞争的焦点,甚至重提芯片禁运法案。

无论如何作为 AI 从业者而言,它证明了开源的强大力量。它向世界展示了,即便在资源有限的情况下,也能实现突破性的技术进展。这种开放共享的 Geek 精神,正是推动 AI 领域蓬勃发展的重要动力。
本篇文章来源于微信公众号: 螺丝刀AI

 关注微信公众号
关注微信公众号